

Windows 10のサポート終了に伴い、PC1台が引退する。
いままでかなり古いPCでこのサイトを運営していたが、これを機にこの古いPCに入れ替えることにした。
以前、一度だけHDDを取り付けて動かしたことがあったので、すぐに復旧させられるかな…と作業を始めた。
作業開始日時は2025年8月17日 10:00、サクッとやっちまおうと、元々ついていたストレージを外し、旧PCからディスクを付け替える。
この作業自体は難しくなく、15分くらいで掃除も含めてできたと思う。
電源投入…しかし、起動しない。
発生したトラブル
超古いPCのSSDやHDDを、古いPCに取り付けて起動するという簡単な作業…だったはずだった。
PCのスペック
| 項目 | 超古いPC | 古いPC |
|---|---|---|
| 型番 | Gateway DX4840 | iiyama ID7i-GS5150-i5-LX |
| CPU | Intel Core i5-750 (第1世代/Lynnfield/2009年) | Intel Core i5-4590 (第4世代/Haswell-DT/2013年) |
| Memory | 32GB (8GBx4) | 32GB (8GBx4) |
| SATA | SATA (時代的に 3 Gb/s? もしかしたら 1.5 Gb/s) | SATA3 (6 Gb/s) |
| LAN | Intel 82574L (内蔵のRealtek RTL8111はドライバがないため動かない) | ← 取り外してこちらへ |
| ESXi | 7.0U2a (allowLegacyCPU=true指定で動いている) | ← このバージョンのまま移行 |
こうしてみると、GatewayのPC凄いな。
メモリーは32GB搭載できたし、SATAで8TBのHDDもちゃんと使えた。
電源のファンが壊れたりもしたけど、それ以外は大きな障害もなく10年以上動いてくれた。
iiyamaのPCは、ちょっと必要になって中古で購入したもの。
これも古いけど、Gatewayの電源故障時に一時的にHDDを差し替えて動作した実績(ESXi 6.5時代)があるので、これに切り替えようかなと。
切り替え作業
やることは簡単。
- GatewayのSSD/HDDを外して、iiyamaに付け替える。
- GatewayのLANボードを外して、iiyamaに付ける。
- Gatewayのグラフィックカードを外して、iiyamaに付け替える。
これだけで起動するはずだ。
iiyamaのPCは、WindowsをUEFIで起動できるようにしていた。
でも、使用していたESXi 7.0U2aはMBRでシステムをインストールするようだ。
BIOSをUEFIからLegacyに変更すると、ブートローダーが読み込まれるようになった。
でも、立ち上がってこない…
SSD破損
システムを起動したとき、
- ブートローダーで、vmx.v00が表示されたところで長時間待たされ、待っていると fatal error 8 が表示されて先に進まない。
- 数回リセットしたところ、vmx.v00がサクッと通過した!よし!と思ったら、ESXiの起動中に nfs41client loaded successfully が表示された後でフリーズ。
- その後は、vmx.v00が表示されたところで長時間待たされ、待っていると fatal error 8 が表示されて先に進まない。
となり、Web UIも表示されないし、仮想マシンも立ち上がることはなかった。
結論からすると、SSDで50個の不良セクターがあり、それが原因でディスクがまともに読み出せないのが原因のようだった。
仮想マシンの救出
この段階では、SSDに不良セクターがあることには気付いていなかったが、起動しないんじゃしょうがない。
SSDの中にある仮想マシンを救出し、SSDにESXiをインストールし直すことにした。
小さめなシステムでも40GB、このブログでも多少の余裕をみて120GB、NAS的な動作をさせるシステムはかなりのディスク容量を割り当てている。
ということで、ただ取り出せるだけでは駄目で、速度も重要。
仮想PC+USBのHDDマウントキット(断念)
ホームラボには、SATAのデバイスを接続して、USBを経由してマウントできる装置がある。
Windows 11 ProでVMware Playerを動かしていて、ゲストにはたまたまUbuntu 24.04 desktopも動いていたので、これでデーターを取り出そうとした。
だが、この場合の問題は転送速度だった。
上記装置はUSB2.0。
遅すぎて無理。
仮想PC+物理ディスクのマウント(断念)
メインPCにSATAで接続して、VMware Playerのゲストから物理ディスクをマウントし、データーを取り出すことにした。
ゲストから物理ディスクをマウントするために、ディスクをアンマウントしておく必要がある。
FUJITSU / クラウドユーザーガイド(コンピューティング:ディスクの認識を外す設定方法(アンマウント手順):Windows系OSの場合)
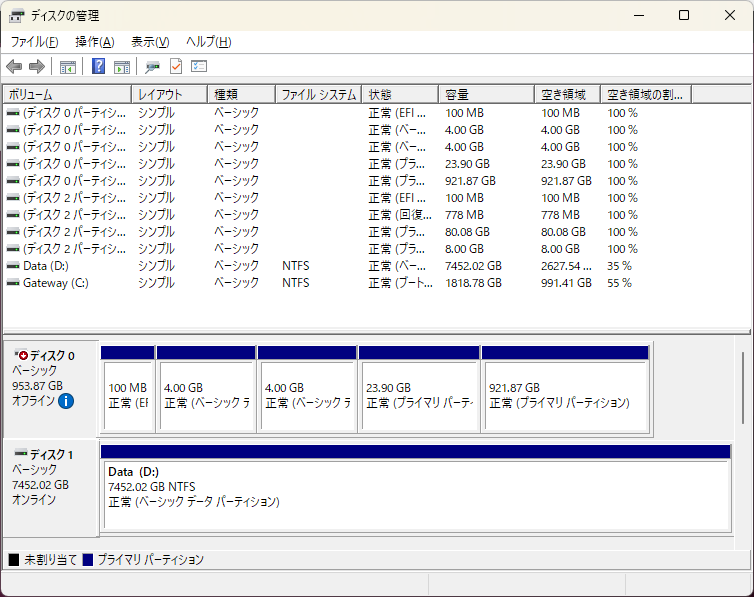
ディスクをSATAで接続し、Windows 11を起動すると、いくつかのパーティションがマウントされた状態になっている。
普通はその方が便利なはずだけど、今回の場合はディスクそのものを仮想PCにマウントさせたい。
しかし、一部のパーティションが利用されている状態だと、ディスクのマウントに失敗する。
ディスクをアンマウントすることを知らなかったため、管理者権限が必要なの?と管理者でVMware Playerを起動。
これが必要なことなのかどうか確認できていないが、メモしておく。
これらを経て、仮想システムで当該ディスクを物理的にマウントできたのだが、以下の問題が発生した。
- データーを取り出すのにcpコマンドを使っていたが、SSDが破損しているため、エラーが発生する。
- 仮想PCでエラーを示すメッセージボックスが表示される。
- エラーをcpコマンドに伝えることを選択したが、繰り返しエラーのメッセージボックスが表示され、一向に先に進まない。
- これはキツいなーと思い、メッセージボックスでキャンセルを選択すると、ゲストが強制終了する。
まともに動かなくて無理。
作業用PCをUbuntuにする
幸い、ホームラボのメインPCは、Windows 11 ProとUbuntu 22.04 desktopのデュアルブート環境。
これでやってみよう。
メインPCにSSDを接続して起動したところ、FATのパーティションが自動的にマウントされていた。
必要ではないけれど、一応マウントを解除するか…と「ディスク」を起動。
以下の通り、不良セクターが報告された。
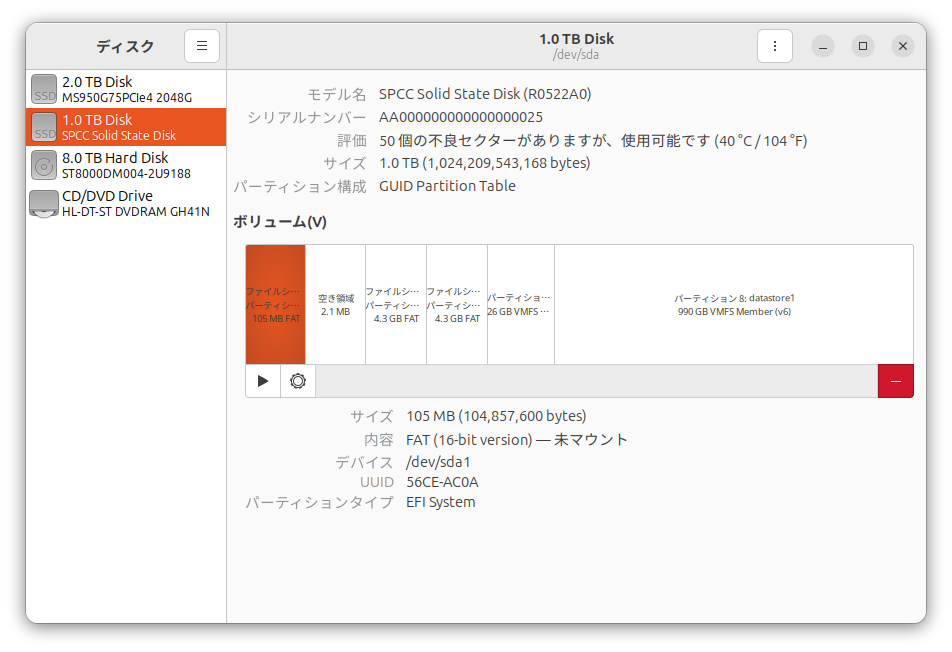
どうやらこれが、ESXiがブートローダーで止まったり、その先のカーネル起動で止まったりと、安定しない原因であり、仮想PCでディスクマウントしたときに、cpコマンドでエラーのメッセージボックスが連続で表示される原因だったようだ。
すべての復旧作業が終わってから、S.M.A.R.T.の情報を表示させてみた。
50というのは、きっと以下の2項目の合計。2025/05/26 追記
$ sudo smartctl -x /dev/sda
...
SMART Attributes Data Structure revision number: 1
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAGS VALUE WORST THRESH FAIL RAW_VALUE
1 Raw_Read_Error_Rate -O--CK 100 100 050 - 0
5 Reallocated_Sector_Ct -O--CK 100 100 050 - 25
9 Power_On_Hours -O--CK 100 100 050 - 30910
12 Power_Cycle_Count -O--CK 100 100 050 - 2586
160 Unknown_Attribute -O--CK 100 100 050 - 590
161 Unknown_Attribute PO--CK 100 100 050 - 53
163 Unknown_Attribute -O--CK 100 100 050 - 10
164 Unknown_Attribute -O--CK 100 100 050 - 119146
165 Unknown_Attribute -O--CK 100 100 050 - 279
166 Unknown_Attribute -O--CK 100 100 050 - 182
167 Unknown_Attribute -O--CK 100 100 050 - 254
168 Unknown_Attribute -O--CK 100 100 050 - 7000
169 Unknown_Attribute -O--CK 100 100 050 - 97
175 Program_Fail_Count_Chip -O--CK 100 100 050 - 0
176 Erase_Fail_Count_Chip -O--CK 100 100 050 - 0
177 Wear_Leveling_Count -O--CK 100 100 050 - 0
178 Used_Rsvd_Blk_Cnt_Chip -O--CK 100 100 050 - 25
181 Program_Fail_Cnt_Total -O--CK 100 100 050 - 0
182 Erase_Fail_Count_Total -O--CK 100 100 050 - 0
192 Power-Off_Retract_Count -O--CK 100 100 050 - 177
194 Temperature_Celsius -O---K 100 100 050 - 40
195 Hardware_ECC_Recovered -O--CK 100 100 050 - 74522804
196 Reallocated_Event_Count -O--CK 100 100 050 - 590
197 Current_Pending_Sector -O--CK 100 100 050 - 25
198 Offline_Uncorrectable -O--CK 100 100 050 - 590
199 UDMA_CRC_Error_Count -O--CK 100 100 050 - 12
232 Available_Reservd_Space -O--CK 100 100 050 - 53
241 Total_LBAs_Written ----CK 100 100 050 - 1779723
242 Total_LBAs_Read ----CK 100 100 050 - 1448452
245 Unknown_Attribute -O--CK 100 100 050 - 1753048
||||||_ K auto-keep
|||||__ C event count
||||___ R error rate
|||____ S speed/performance
||_____ O updated online
|______ P prefailure warning
...
非常にまずそうだ…datastore1からデーターを救出して、このSSDは引退させるしかない。
ディスクからデーターを読み出すのにどうすればいいのかと探してみると、こんな情報があった。
有志が作ったvmfsパーティションを「読み取り専用」でマウントできるコマンドがあるそうで、その使い方を教えてくれている。
server fault / Copy VM files from ESXi host physical HDD
Windows OS Hub / How to Access VMFS Datastore from Linux, Windows, or ESXi
$ sudo su -
# apt install vmfs6-tools
# mkdir /mnt/datastore1
# vmfs6-fuse /dev/sda8 /mnt/datastore1
VMFS version: 6
# cp -ar /mnt/datastore1/ <バックアップ先のディレクトリ>
この時、
- シン・プロビジョニングで作成した仮想ディスクは、フルサイズでコピーされる。結果的に、シック・プロビジョニング状態に。
- どうやら、cpコマンドはエラー発生時にリトライを繰り返してくれるらしい。時々コピーが止まっていたが、最終的にはコピー完了。
- 物理ディスクをマウントしていた(8TB)が、これは作業用PCには接続しておらず、cpコマンドはエラー終了した。
だった。
結果としては、上手く仮想マシン達を救出できたのではないかと思う。
ChatGPTさんにはddrescueをオススメされたが、既にcpでバックアップを取り始めていたので、cpを続行。
上記の通りcpコマンドはエラー終了しているので、コピーし切れていないファイルがないか確認する必要があった。
これをChatGPTさんに相談したところ、以下を教えてくれた。
# find /mnt/datastore1 -type f -printf "%P|%s\n" | sort > original.txt
# find <バックアップ先のディレクトリ> -type f -printf "%P|%s\n" | sort > backup.txt
差分を確認(diff.txt を見れば「存在しない or サイズが違うファイル」が出ます。)
# diff original.txt backup.txt > diff.txt
コピー漏れだけを抽出(missing.txt に「元にはあるけどコピー先にない or サイズ違いのファイル」が出ます。)
# comm -23 original.txt backup.txt > missing.txt
幸い、コピーできていなかったのは8TBの物理ディスクだけだった。
これはたまたまなのか、そういうものなのか、全く分からない。もし不足していたら、それだけコピーすればいいかなと思う。
復旧作業
新しいSSDを注文したら翌日に届いたので、復旧作業を開始。
ESXiの復旧
ChatGPTさんに聞いたら、ESXi 7.0U2aはIntel Core i5-4590をサポートしていないとのことだった。
そのため、allowLegacyCPU=trueで無理矢理起動する必要がある。
幸い、その状態でインストールができるISOイメージを作成してあったので、それを使ってESXiをインストールした。
BIOSはUEFIに設定した状態でインストールしたけれど、GPTにはならず、MBRでインストールされた。
SSDのサイズは2TBで特に不都合もないので、BIOSをLegacyにしてESXiを起動。
なんかiiyamaは起動が早い。Gatewayの時よりだいぶ早い気がする。
ネットワークを手動で設定してシャットダウン。
HDD2台を取り付けて起動してWeb UIにログインし、1台はデーターストアとして認識していること、1台はそこに存在していること(これは後で物理マウントする)を確認。
仮想マシン達をアップロード
救出した仮想マシン達をデーターストアーにアップロードしていく。
データーストアブラウザーでそれぞれのディレクトリを作り、仮想マシン1台につき6ファイルアップロードした。
拡張子でいうと、
- nvram(VMの仮想BIOS/UEFIの設定を保存するファイル)※2
- vmdk x 2(ディスクの定義と内容)※1
- vmsd(スナップショットの管理情報)
- vmx(仮想マシンの設定が書かれている)※1
- vmxf(主にチーム/クラスタ構成、vSphere関連のメタデータ)
をアップロードした。
※1:必須
※2:allowLegacyCPU=trueの環境下では、仮想PC達をUEFIで起動する必要があり、ウチでは必須。
面倒だなと思ったのは、
- ディレクトリを指定して丸ごとアップロードはできない。1つ1つファイルを選択してアップロードする必要がある。
- ホームラボは一応1000BASE-Tだけれど、ディスクをアップロードするのにはそれなりに時間が掛かる。
ということで。
フォルダをアップロードして、寝ている間に全部アップロードできました!ということにはならない。
SSDをメインPCに接続してデーター転送することも考えたが、データーストアのパーティションは特殊なので無理っぽい。
バックアップをとったHDD、つまりメインPCのHDDを取り外し、ESXiに取り付ければ一気に転送できそうな気もするが、それはそれで面倒なので諦めた。
仮想マシン達をアップロード(案)
これはやってみていないのだけれど、ChatGPTさんに聞いてみたら、できるよと。
$ scp -r ./MyVMFolder/ root@<ESXiのIPアドレス>:/vmfs/volumes/datastore1/
これなら、寝ている間に全ての仮想マシン達を転送できたかも。
RawDeviceMapping
ディスクを直接マウントするために、以下のコマンドを実行していた。
これを今回の環境に合わせて実行し、仮想ディスクを作成する。
[root@ESXi:~] mkdir /vmfs/volumes/datastoressd/RawDeviceMapping
[root@ESXi:~] vmkfstools -z /vmfs/devices/disks/t10.ATA_____WDC_WD80EAZZ2D00BKLB0_____________________________WD2DCA31XYSK /vmfs/volumes/datastoressd/RawDeviceMapping/wd8tb.vmdk
仮想マシンからディスクを外し、再度付け直す。
まず、SCSI 0:1にこれを割り当てていたことを確認。
一旦、デバイスを削除して、SCSI 0:1に仮想ディスクを追加し直す。
デバイス削除時に、ディスクを本当に削除するようなチェックボックスが出てくるので、これはチェック"しない"ように注意!
これで、ディスクを物理マウントしたシステムが正常に起動した。
アップロードしたシステムを起動する
起動するときに、こんな質問がある。
今回のケースでは「移動」として扱うのがよろしいかと。
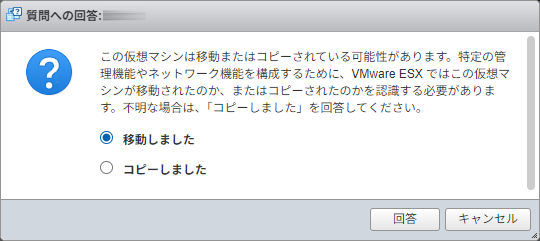
これで問題なくシステムが起動してきた。
ESXiの設定
復旧したはいいが、いくつかESXiの設定をしておかなければ。
今回は復旧最優先だったけれど、モニターレス運用をしている場合、SSH接続制限に関する設定は先にやっておけるといいかもしれない。
ハードウェアクロック
ESXiはBIOSの時間、ハードウェアクロックをUTCとして扱う前提だそうで。
iiyamaはいままでWindowsで動かしていたこともあって、ハードウェアクロックはJSTになっていた。
この場合、ESXiは日本時間(+09:00)をUTCと解釈してシステムクロックに移してサービスを開始。
しかし、NTPクライアントを動作させても時間が合わない。
ChatGPTさんに相談してみたところ、1,000秒を超える違いがあると時間を合わせることを止めてしまうからだそうだ。
ちなみに、ゲストのUbuntu達は、systemd-timesyncdがNTPサーバーと時間調整している。
こちらは1,000秒のような制限はないので、すぐに時間が正しくなるということだった。
ChatGPTさんは、ESXiにはハードウェアクロックを設定する手段がなく、BIOS設定画面で時間を設定しなければならない、という。
でも、ここで手動で時計を設定したからなのか、その後にNTPクライアントを起動したからなのかは分からないが、ハードウェアクロックは更新されていた。
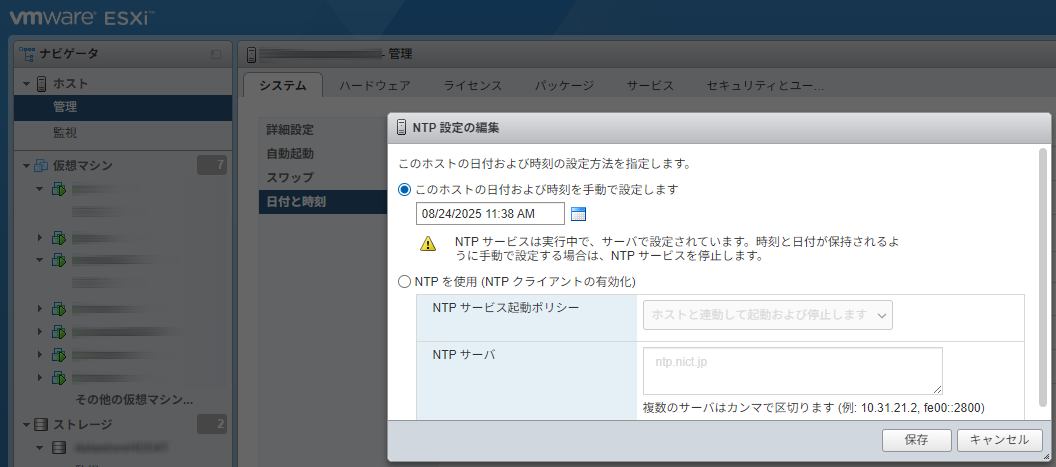
いずれにしても、ハードウェアクロックはUTCであることを意識して時間設定をしておく。
Web UIのタイムアウト
ちょっと大きなディスクをアップロードしようとして、席を外して戻ってくると、ログアウトした状態になっている。
そして、ログアウトしたその画面でログインし直しても、ダッシュボードに行けない(ページのリロードが必要)。
行った操作が正常終了したのかどうか、別の画面に確認しに行く必要が出てくる。
対策として、タイムアウトしないようにする。
Web UIのナビゲーターにある ホスト-管理 をクリックする。タブ「システム」、サブメニュー?の詳細設定が選択されている。
UserVars.HostClientSessionTimeout(Host Client セッションのデフォルトのタイムアウト (秒)) を 0 に設定する。
ただ、これでもChromeがタブを休止させたりするみたいで、エラー画面で止まっていたりする。
どうすればいいんですかね、これは。
証明書
ホームラボでは自前のルート認証局を運用しているので、その認証局で署名した証明書が使えるようになっている。
Webサーバーの証明書を運用するためには秘密鍵が必要だけれど、そんなものはバックアップしていない。
新たな秘密鍵を作り、その秘密鍵で生成された証明書署名要求にオレオレ認証局で署名する。
Web UIのナビゲーターにある ホスト-管理 をクリックし、タブ「セキュリティとユー...」をクリックする。
そして、証明書をクリックし、新しい証明書のインポートをクリックする。
「証明書をインポートします」ダイアログが表示されるので、「FQDN署名要求の生成」をクリックする。
証明書署名要求が表示されるので、クリップボードに入れる。
これにオレオレ認証局で署名した後、できあがった証明書を貼り付けてインポートすればOK。
ホスト名の変更
ホスト名はSSHで接続し、以下のコマンドで変更できる。
[root@localhost:~] esxcli system hostname set --fqdn=esxi.hogeserver.hogeddns.jp
[root@esxi:~] esxcli system hostname get
Domain Name: hogeserver.hogeddns.jp
Fully Qualified Domain Name: esxi.hogeserver.hogeddns.jp
Host Name: esxi
変更すると、Web UIでの表示も変わる。
Zabbixで監視
管理 → セキュリティとユー... → ユーザー でユーザーを追加する。
ホスト → アクション → 権限 でユーザーを追加し、そのユーザーに読み取り権限を与える。
後は、Zabbixでホストがディスカバリーされれば、監視ができる。
S.M.A.R.T.の監視
SSDの不良セクタがたまたま見つかったから良かったようなものの、もし見つからなかったら…と考えるとおっかないことこの上なし。
かといって、健康状態を監視するとなると、それ用の監視システムを入れるとか、Zabbixでスクリプトを実行するとか、そんな方法が一般的なようだ。
お手軽な監視を実装するなら、SSHでログインしてS.M.A.R.T.(Self-Monitoring, Analysis and Reporting Technology)の情報を確認し、異常が見つかったらメールでレポートを送るとか、そんな方法になる。
やることは…
- SSHで接続できるIPアドレスを制限。
- ホストが起動すると同時に、SSHサービスを起動。
- SSHサービスの警告がうざったいので止める。
- Ubuntuから定期的にSSHで接続し、S.M.A.R.T.を確認して、異常があったらメールで通知。
といったところ。
SSHで接続できるIPアドレスを制限
ESXiがあれだけ警告するのだから、SSHを開けっぱなしにすることはリスクが高いのだろう。
だけど監視のためには開けっぱなしにする必要があるので、せめて接続元となるIPアドレスくらい制限するか…
この操作は、SSH接続でやると必ず失敗する。
DCUI(ホストPCで直接Shell操作するUI)でしか実施できない。
- Web UIでホスト → アクション → サービス → コンソール Shell の有効化。
- ESXiの黄色い画面で、[Alt]+[1]でコンソール画面に切り替え。
コンソール画面が表示されたら、root等でログインし、以下を実行する。
[root@esxi:~] esxcli network firewall ruleset set --ruleset-id sshServer --allowed-all false
[root@esxi:~] esxcli network firewall ruleset allowedip add --ruleset-id sshServer --ip-address <メインPCのIPアドレス>
[root@esxi:~] esxcli network firewall ruleset allowedip add --ruleset-id sshServer --ip-address <監視に使うサーバーのIPアドレス>
1行目は、どんなIPアドレスからのSSH接続でも受け付ける、を無効にする。
この操作によって、接続中のSSHは閉じられてしまうので、SSH接続では実施ができない。
2行目で、メンテナンスで使用するPCのIPアドレスを許可している。
3行目で、監視に使うサーバーのIPアドレスを許可している。
2~3を先に実施し、最後に1行目を実施すればいいと思うでしょ?
ところがこんなエラーが表示されるのだった。
[root@esxi:~] esxcli network firewall ruleset allowedip add --ruleset-id sshServer --ip-address <メインPCのIPアドレス>
Couldn't update allowed ip list when allowed-all flag is true.
一度、メンテナンスで使用するPCのIPアドレスを登録できれば、後は遠隔でもIPアドレスを追加することができるようになる。
ホストが起動したらSSHサービスも起動する
この設定はWeb UIでできた。
TSM-SSHがSSHのサービスで、ポリシーを「ホストと連動して起動及び停止します」にする。
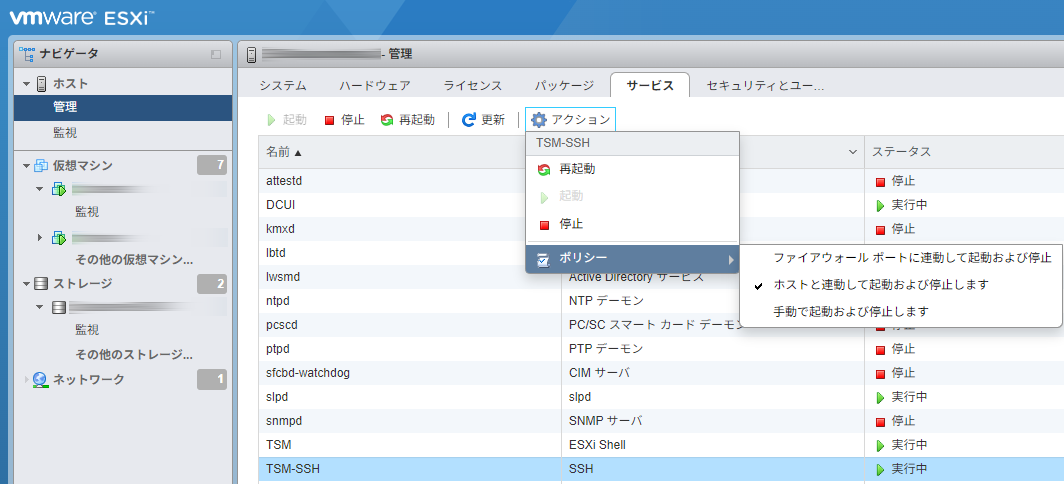
SSH有効の警告を止める
これもWeb UIで設定できた。
管理 → システム → 詳細設定 で以下を設定。
UserVars.SuppressShellWarning = 1
RSA鍵でESXiに接続できるようにする
S.M.A.R.T.の監視のために、ESXiにrootで接続してコマンドを実行する(まずは安全性より実装を優先)。
Ubuntuサーバーでcronを設定し、rootユーザーで監視スクリプトを実行することにした。
接続用にRSA鍵を作る。
$ sudo su -
# ssh-keygen -t rsa -b 4096 -f ~/.ssh/id_rsa_esxi
Generating public/private rsa key pair.
Enter passphrase (empty for no passphrase):<パスフレーズには何も入力しない>
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa_esxi
Your public key has been saved in /root/.ssh/id_rsa_esxi.pub
The key fingerprint is:
SHA256:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX root@hoge
The key's randomart image is:
+---[RSA 4096]----+
|XXXXXXXXXXXXXXXXX|
|XXXXXXXXXXXXXXXXX|
|XXXXXXXXXXXXXXXXX|
|XXXXXXXXXXXXXXXXX|
|XXXXXXXXXXXXXXXXX|
|XXXXXXXXXXXXXXXXX|
|XXXXXXXXXXXXXXXXX|
|XXXXXXXXXXXXXXXXX|
|XXXXXXXXXXXXXXXXX|
+----[SHA256]-----+
ESXiに公開鍵を登録する。
このやり方は全然知らなかったけれど、Geminiさんが教えてくれた。
# ssh-copy-id -i ~/.ssh/id_rsa_esxi.pub root@<ESXiのIPアドレス>
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa_esxi.pub"
The authenticity of host '<ESXiのIPアドレス> (<ESXiのIPアドレス>)' can't be established.
ECDSA key fingerprint is SHA256:XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX
This key is not known by any other names
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
(root@<ESXiのIPアドレス>) Password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@<ESXiのIPアドレス>'"
and check to make sure that only the key(s) you wanted were added.
ただし、rootの場合だけは公開鍵の確認対象ファイルが違うそうで、ESXiにログインしてroot用のファイルに公開鍵をコピーした。
※初めての公開鍵登録だったのでこうしたけれど、最初から/etc/ssh/keys-root/authorized_keysに公開鍵を入れるのがスムーズかも。
[root@ESXi:~] cat .ssh/authorized_keys >> /etc/ssh/keys-root/authorized_keys
こうすると、公開鍵を使ってパスワードなしで接続ができるようになる。
# ssh -i .ssh/id_rsa_esxi root@<ESXiのIPアドレス>
これで、監視用スクリプトがパスワード入力なしで実行できるようになった。
監視用のスクリプトを作成
監視したいデバイスの名前を確認する。
Web UIで確認してもいいし、コマンドラインから確認してもいい。
[root@ESXi:~] esxcli storage core device list
t10.ATA_____SPCC_Solid_State_Disk___________________AA250312S302KG01541_
Display Name: Local ATA Disk (t10.ATA_____SPCC_Solid_State_Disk___________________AA250312S302KG01541_)
Has Settable Display Name: false
...
t10.ATA_____WDC_WD40EZRZ2D22GXCB0_________________________WD2DWCC7K3SY0PVK
...
t10.ATA_____WDC_WD80EAZZ2D00BKLB0_____________________________WD2DCA31XYSK
...
この長いのが監視したいデバイスの名前。
この情報を渡して、GeminiさんにS.M.A.R.T.情報を抽出するスクリプトを作ってもらった。
/usr/local/bin/esxi-smart-report.sh
#!/bin/bash
# ESXiホストのユーザーとIPアドレス
ESXI_USER="root"
ESXI_HOST="<ESXiのIPアドレス>"
ESXI_KEY_FILE="/root/.ssh/id_rsa_esxi" # 鍵ファイルの絶対パスを指定
# 監視するデバイスIDの配列
declare -a devices=(
"t10.ATA_____SPCC_Solid_State_Disk___________________AA250312S302KG01541_"
"t10.ATA_____WDC_WD40EZRZ2D22GXCB0_________________________WD2DWCC7K3SY0PVK"
"t10.ATA_____WDC_WD80EAZZ2D00BKLB0_____________________________WD2DCA31XYSK"
)
# 各デバイスのSMART情報を取得
for device_id in "${devices[@]}"
do
echo "### $device_id ###"
ssh -i "$ESXI_KEY_FILE" "$ESXI_USER@$ESXI_HOST" "esxcli storage core device smart get -d \"$device_id\""
echo ""
done
実行してみると、こんな結果が得られる。
# chmod +x /usr/local/bin/esxi-smart-report.sh
# esxi-smart.sh
### t10.ATA_____SPCC_Solid_State_Disk___________________AA250312S302KG01541_ ###
Parameter Value Threshold Worst Raw
--------------------------------- ----- --------- ----- ---
Health Status OK N/A N/A N/A
Read Error Count 100 50 100 0
Power-on Hours 100 50 100 129
Power Cycle Count 100 50 100 9
Reallocated Sector Count 100 50 100 0
Drive Temperature 100 50 100 40
Write Sectors TOT Count 100 50 100 90
Read Sectors TOT Count 100 50 100 226
Sector Reallocation Event Count 100 50 100 0
Pending Sector Reallocation Count 100 50 100 0
Uncorrectable Sector Count 100 50 100 0
### t10.ATA_____WDC_WD40EZRZ2D22GXCB0_________________________WD2DWCC7K3SY0PVK ###
...
続いて、この結果の中で、
- Reallocated Sector Count
- Drive Temperature
の異常を検知して表示してくれるスクリプトを、Geminiさんに作ってもらった。
/usr/local/bin/esxi-smart-report.sh
#!/bin/sh
# esxi-smart.shの出力を取得
smart_output=$(esxi-smart.sh)
ALERT_FOUND=0
# ドライブごとにチェック
echo "$smart_output" | awk '
BEGIN {
FS="\n"; RS="\n\n";
}
/---/ {
drive_name = $1
sub(/### /, "", drive_name)
sub(/ ###/, "", drive_name)
# 不良セクターのチェック
for(i=1; i<=NF; i++) {
if ($i ~ /Reallocated Sector Count/) {
split($i, a, " ")
reallocated_count = a[length(a)]
if (reallocated_count > 0) {
print "警告: " drive_name "に不良セクターが検出されました。数量: " reallocated_count
found = 1
}
}
}
# 温度のチェック
for(i=1; i<=NF; i++) {
if ($i ~ /Drive Temperature/) {
split($i, a, " ")
temperature = a[length(a)]
if (temperature > 50) {
print "警告: " drive_name "の温度が異常に高いです。現在の温度: " temperature "℃"
found = 1
}
}
}
}
' > /tmp/smart_alert.txt
# /tmp/smart_alert.txtに内容があれば、それを標準出力に出力
if [ -s /tmp/smart_alert.txt ]; then
echo "--- ESXi SMART Warning ---"
cat /tmp/smart_alert.txt
echo "--------------------------"
ALERT_FOUND=1
fi
# 一時ファイルを削除
rm -f /tmp/smart_alert.txt
exit $ALERT_FOUND # 正常終了なら0、警告があれば1を返す
ダミーの結果出力コマンドを作ってテストした結果。
# chmod +x /usr/local/bin/esxi-smart-report.sh
# esxi-smart-report.sh
--- ESXi SMART Warning ---
警告: t10.ATA_____SPCC_Solid_State_Disk___________________AA250312S302KG01541_に不良セクターが検出されました。数量: 1
警告: t10.ATA_____WDC_WD40EZRZ2D22GXCB0_________________________WD2DWCC7K3SY0PVKの温度が異常に高いです。現在の温度: 51℃
--------------------------
ここまでできていれば、Cronにこのesxi-smart-report.shを実行するスクリプトを登録すれば、警告があったときにメールが送られる。
※このサーバーは、LogCheckの結果を送信するために、投稿されたメールをメインのメールサーバーにリレーするだけのPostfixが動いている。
管理者宛てのメールは携帯では受けていないので、携帯で受けられるアドレスを設定。
夏でくっそ暑いので、しばらくの間1時間に1回レポートさせてみる。
/etc/cron.d/esxi-smart-report
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=hoge@hogeserver.hogeddns.jp
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed
56 * * * * root esxi-smart-report.sh
※メールアドレスはマスクした。
大丈夫だと思ったら、頻度を日に1回とか、週に1回とかに落としていくことにする。
停電からの復旧
電源投入
何らかの理由で停電したとする。
停電から復旧したときに、自動で電源が入るようにするには?
というと、BIOSの設定になる。
Power Managementのようなセクションで、Restore on AC/Power Lossといった項目がそのような状況を表している。
この項目を以下のいずれかで設定すれば良さそうだった。
- 常に電源を入れたい場合
→ Always On, Power Onといった項目。 - 電源が入っていたなら入るし、切れていたらそのままにしたい場合
→ Last State
これで、稼働中に停電が発生しても、復電すればPCは立ち上がってくる。
ゲストの自動起動
各ホストを起動するように設定したのに、自動起動してこない…と思ったら、以下の設定が抜けていた。
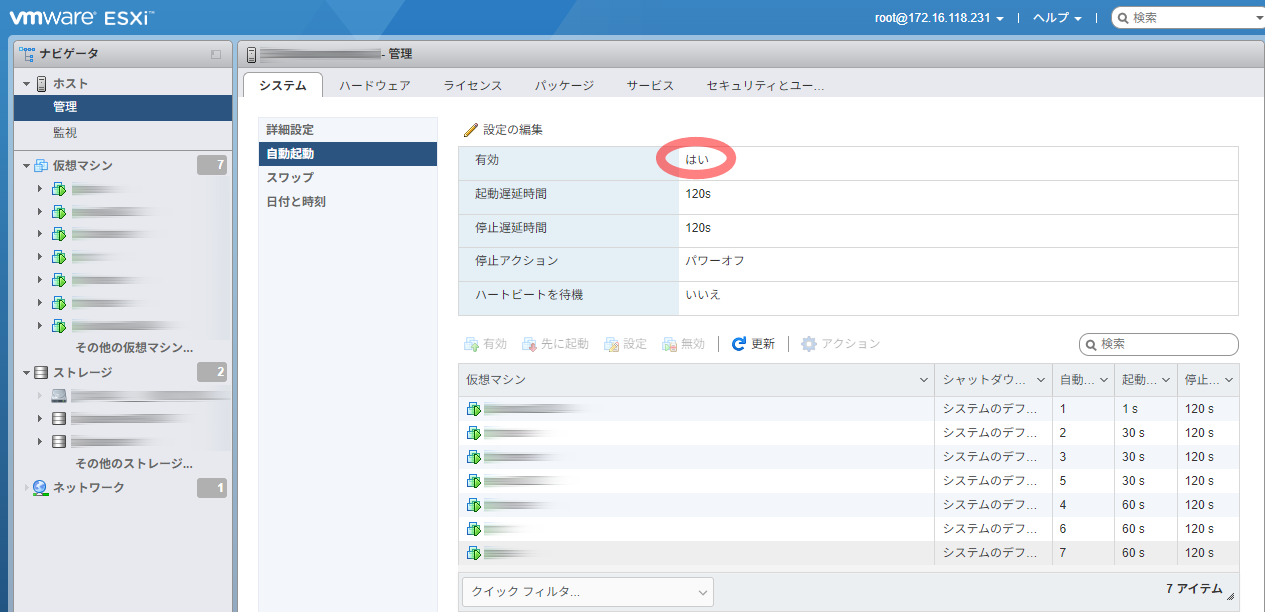
まず、自動起動が有効でなければならない。
続いて、それぞれの仮想マシンを自動起動するように設定する。
設定項目には以下がある。
| 項目名 | 設定値と意味 |
|---|---|
| 起動遅延時間 | 前のホストが起動し始めてからどのくらい待つのかを設定。 vm1: 30, vm2: 30 だった場合、vm1はESXiが起動してから30秒後、vm2は60秒後に起動。 |
| 停止遅延時間 | 前のホストがシャットダウンしなかった場合に、強制的に停止処理が始まる時間。 長めの時間を設定していても、前のホストがシャットダウンしたら、次のホストはシャットダウンを始める。 |
| 停止アクション※ | 画面では、システムデフォルトとしてパワーオフが選択されている。 パワーオフは、open-vm-toolsが入っていると、シャットダウン処理になるそうだ。 |
| ハートビートを待機※ | はい、にすると、open-vm-toolsが入っていたら、それと通信して起動を判断。 DBサーバーが起動した後でアプリケーションサーバーを起動したい場合などに使うそうだ。 |
※印は試していない。ChatGPTさんが教えてくれたもので、間違っている可能性も結構ある。
これで自動復旧すると思う。
メンテナンスモード
サーバーを再起動させるときに、メンテナンスモードになっていないと警告される。
でも、メンテナンスモードというのは、「ESXiは何もしませんよ」というモードであるように思われる。
メンテナンスモードにしてサーバーを再起動すると、仮想マシンの自動起動が失敗するのだ。
ホームラボでは、ESXiをスタンドアロンで動かしている。
- 稼働しているUbuntu達にはopen-vm-toolsが入っていて、ESXiからのシャットダウン指示には従うことができる状態。
- ESXiに上位の管理システムがあるわけでもなく、何かと協調することもない。
このような環境なので、メンテナンスモードに入れる必要はなかった。
さいごに
入れ替えた感想
GatewayからiiyamaのPCに入れ替えてみた感想は、だいぶ早くなったなー、だった。
このサイトは、キャッシュのプラグインが効いているので、ページの閲覧に差はない。
これ以外の体感速度が全然違う。
- WordPressのダッシュボードへのアクセス、投稿ページへの移動等、すべての操作。
- NextcloudをWebでのファイル一覧、ファイル表示。
- Sambaで共有しているフォルダの閲覧、写真や動画のサムネイル表示等。
- Wi-Fi接続時のDHCP操作。
- SSHで接続する際のログイン時間。特にサーバーごとの1回目。
- 等々
すべてに一拍の待ちが入る感じだったのだけれど、これがなくなって、即時動き始めて至極快適。
この差は何?GatewayのPCが超古いから?
でも、一拍待って動き出したら、それなりに動いていたんですよ、実際。
快適さの理由
GeminiさんとChatGPTさんに聞いてみたところ、
- Intel 第1世代CPU→第4世代CPUによる命令セットの改善
- AES-NI対応で暗号化速度が向上
- 仮想化支援機能の改善で仮想マシンの実行効率向上
- メモリーの改善
- メモリクロックが 1333MHz → 1600MHz に向上
- チップセットの改善
- SATAが3Gbpsから6Gbpsに向上
といった改善により、ESXiのオーバーヘッドが減って反応が良くなったということのようだ。
触ってみれば分かる、激変と言えますよ、実際。
それでも、この第4世代のCPUはサポート対象外。
それはきっと、今のCPUはもっと改善されていて、仮想マシンはもっと動きやすくなっているってことなのだろう。
生成AIとの会話
今回から、Geminiさんだけでなく、ChatGPTさんにも協力してもらった。
それぞれ、色々と教えてくれるのだけれど、今回のテーマについての会話では、
- 1回の回答の中で矛盾が生じている
- まるで正反対のことを教えられる(できる→できない、こうなる→そうはならない)
といったことが多発した。
これによって結構痛い目も見た。
原因としては、
- 項式の設計思想が、安定運用のためにはvCenterが必須と考えている。
- 学習データーがエンタープライズのものなので、それに寄せた推論になりがち。
というのがあって、更にvCenterあり・なしで動作が違っているので、最悪のシナリオになるとみられる。
確かに自分でも思うよね、自宅でサーバーを運用しているようなケースはごく限られていると。
色々なことがあったけど
結果としては色々と学習できたし、実装もできた。
ストレージの健康状態を監視できるようになったのは、とても良かった。
色々と痛い目を見た部分もあるけれど、スクリプトをGeminiさんやChatGPTさんがサクッと書いてくれるのは、非常に楽。
データーの損失も防ぐことができたし、サービスの使用感も格段に良くなったので、結果としては成功だったと思う。
これからしばらく頑張ってもらいますよ、iiyamaのPCさん。
よろしくね。


コメントはこちらから お気軽にどうぞ ~ 投稿に関するご意見・感想・他