

会社で共有フォルダに置いたPDFを検索しやすくしたい、という要望を受けた。有料サービスを使えば認識精度も高く、検索も便利になるだろうけれども、とりあえずお試しの環境を作ってみることにした。
考え方
Samba で共有フォルダを用意し、そこにファイルが置かれたら OCR 処理を掛ける。ただそれだけだけど、どうやって実現するんだろう?
ファイルが置かれたことを検知したら処理を実施する…これを実現するのには以下の記事にある方法が使えそう。
Glide Note / ファイル/ディレクトリの変更を検知してコマンドを実行するincron
OCR 処理は pdfsandwichを利用し、そこからTesseract OCRを呼び出す。過去に Alfresco に OCR 機能を追加したときの経験が流用できそう。当時は Ubuntu16.04 だったので色々ソースからコンパイルをしたけれども、 Ubuntu18.04 ではこの時と同等のバージョンが apt で利用できたのでお手軽。
共有フォルダに置かれた PDF を効率よく検索するにはどうしたら…?あら、Acrobat Reader DC に検索機能があるのか!
Adobe / 高度な検索機能の使用方法(Acrobat DC/Adobe Reader DC)
これで実現できそうだ。
共有フォルダの監視とコマンド実行
共有フォルダの準備
テスト用の環境には Samba がインストールされている(Samba ad dc ではなく、Samba として動作)。名前解決は別サーバーでできるようになっているので、445/tcp だけ開けば良さそう。
$ sudo ufw allow 445/tcp comment "SAMBA SMB over TCP"
テスト用の共有フォルダを作る。
$ sudo mkdir -p /home/samba/share
$ sudo chown nobody:nogroup /home/samba/share
認証せずに使える共有フォルダを設定する。
/etc/samba/smb.conf
[global]
unix password sync = yes
map to guest = bad user
…
[share]
comment = Users Share Directory
path = /home/samba/share
guest ok = yes
browseable = yes
writable = yes
セキュリティ意識ゼロで最低限過ぎるが、これでファイルやディレクトリを作るとこんな感じになるので、テスト利用ならばこれで十分かな。
$ ll /home/samba/share/
total 12
drwxr-xr-x 3 nobody nogroup 4096 Aug 24 11:01 ./
drwxr-xr-x 3 root root 4096 Aug 24 10:40 ../
drwxr-xr-x 2 nobody nogroup 4096 Aug 24 11:01 新しいフォルダー/
-rwxr--r-- 1 nobody nogroup 0 Aug 24 11:01 '新しいテキスト ドキュメント.txt'*
共有フォルダの監視とコマンド実行
Incronのインストールと設定
監視には Incron を使う。とても丁寧にフォローされているこの記事で作業を実施。
HowtoForge / How to run commands on File or Directory changes with Incron on Ubuntu 16.04
$ sudo apt install incron
起動条件とコマンドの指定…エラーが!
$ sudo incrontab -e
user 'root' is not allowed to use incron
今回の変換処理は root で行うので、root を allowed なユーザーにする。
/etc/incron.allow
root
※この1行だけを追加。
日頃使っているエディタは vim なので設定。Default: vim とあるけど、実際には nano が起動してくる。
/etc/incron.conf
…
# Parameter: editor
# Meaning: editor executable
# Description: This name or path is used to run as an editor for editing
# user tables.
# Default: vim
#
# Example:
# editor = nano
editor = vim
エディタを起動して定義を書く。利用できるイベントはマニュアルに書かれている。
ubuntu manuals / incrontab - tables for driving inotify cron (incron)
$ sudo incrontab -e
/home/samba/share IN_CREATE,IN_DONT_FOLLOW /home/samba/ocr.sh $@/$#
保存する。ファイルの実態はココにある。
/var/spool/incron/root
今回とても都合がいいのは「IN_CREATE」というフラグはファイルが作られたときにだけ反応するらしいこと。この後作成するスクリプトで OCR された PDF が置かれるときには反応しない。pdfsandwich というコマンドを利用しているが、PDF は tmp ディレクトリで作成されたものが mv される模様、この場合には反応しなかった。
テスト用のスクリプト作成
テスト用に適当な ocr.sh の中身を定義。
/home/samba/ocr.sh
#!/bin/bash
echo $1 >> /home/samba/test.log
実行権限を付けてテストする。
$ sudo chmod 700 /home/samba/ocr.sh
テスト
$ sudo /home/samba/ocr.sh abc
$ sudo /home/samba/ocr.sh def
$ cat /home/samba/test.log
abc
def
テストログを削除
$ sudo rm /home/samba/test.log
ファイル作成を検知するとコマンドが呼び出されることをテスト
エクスプローラーで share に新しいファイルを作ってみる。
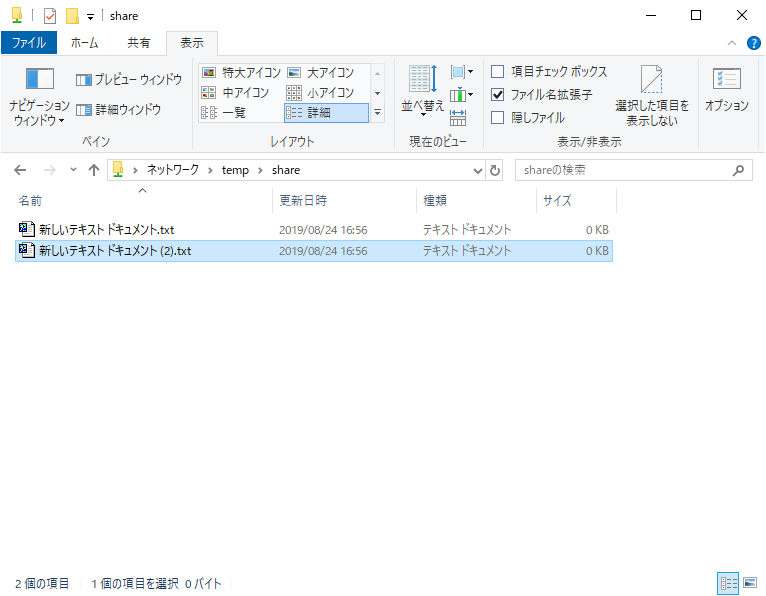
ファイル名がテストログに出力されることを確認する。
$ cat /home/samba/test.log
/home/samba/share/新しいテキスト ドキュメント.txt
/home/samba/share/新しいテキスト ドキュメント (2).txt
※ファイルが作成されたときにだけ反応する incron の定義をしたので、この後ファイル名を変えてもログには出力されない。
PDFをOCRに掛けるスクリプトの作成
必要ライブラリのインストール
機能の呼び出し経路イメージは以下の通り。
pdfsandwich → Tesseract OCR → Leptonica
Ubuntuのパッケージをインストールしてバージョンを確認。
$ sudo apt install leptonica-progs tesseract-ocr tesseract-ocr-jpn tesseract-ocr-jpn-vert pdfsandwich
$ pdfsandwich -version
pdfsandwich version 0.1.6
$ tesseract --version
tesseract 4.0.0-beta.1
leptonica-1.75.3
libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.2) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.3.0
Tesseractの言語データーは以下に配置されていた(括弧内はmd5sum値)。
/usr/share/tesseract-ocr/4.00/tessdata/jpn.traineddata (182528e3ec6f0ea33704c4607ba3518d)
/usr/share/tesseract-ocr/4.00/tessdata/jpn_vert.traineddata (9c9a57f86aed3797b067bfa107383418)
確認してみると、tesseract-ocr/tessdata_fast にあるデーターと一致しており、安心して使い始められる状態と分かった。
動作設定
PDF を ImageMagick で処理できるようにセキュリティポリシーを緩める。対象となる問題は脆弱性、Ghostscript のバージョン9.24で対処されているようなので多分問題はないと思われる。
Carnegie Mellon University / Ghostscript contains multiple -dSAFER sandbox bypass vulnerabilities
Ghostscript / History of Ghostscript Versions 9.25(リンク切れ https://ghostscript.com/doc/9.25/History9.htm#Version9.25)
$ ghostscript -v
GPL Ghostscript 9.26 (2018-11-20)
Copyright (C) 2018 Artifex Software, Inc. All rights reserved.
/etc/ImageMagick-6/policy.xml
…
<policymap>
…
<!-- disable ghostscript format types -->
<policy domain="coder" rights="none" pattern="PS" />
<policy domain="coder" rights="none" pattern="EPS" />
<policy domain="coder" rights="read|write" pattern="PDF" />
<policy domain="coder" rights="none" pattern="XPS" />
</policymap>
スクリプトの作成
PDF ファイルが置かれたら反応して OCR に掛ける。種類で見分ける。
UX MILK / 【file】Linuxでファイルの種類を取得するコマンド
それマグで! / bashでif に正規表現を使った文字列マッチ条件分岐
排他制御も考えたい。ファイルは1つずつ処理して行ければ良い。っていうか、複数スレッドで Tesseract が呼び出されるとフリーズする場合があるみたい。
ubuntu manpage / flock - ファイルロックを取得し、そのロックを保持するコマンドを実行する
処理結果となったファイルの属性をコピーしたい。
Qiita / パス文字列からファイル名などを抜き出す
それマグで! / 指定したファイルの属性情報だけをコピーする。更新日・権限を揃えたい。
っていう超適当なスクリプトを作る。
/home/samba/ocr.sh
#!/bin/bash
# ファイルが作られてから少しだけ待つ(転送中かもしれないから)
sleep 5
# ファイルの種類を取り出す
KIND=`file "$1" | sed -e "s/^.*: //"`
# PDFだったらOCRに掛ける
if [[ $KIND =~ ^PDF.+$ ]]; then
# 縦書き対応、時間がかかる
#flock /home/samba/ocr.lock pdfsandwich "$1" -verbose -rgb -lang jpn+jpn_vert
# 横書きのみ、早い
flock /home/samba/ocr.lock pdfsandwich "$1" -verbose -rgb -lang jpn
# 処理後のファイル名を生成
DEST=${1%.*}_ocr.${1##*.}
# ファイルの属性だけをコピー
cp --preserve=mode,ownership --attributes-only "$1" "$DEST"
fi
作ったスクリプトに実行権限を付けておく。
$ sudo chmod 700 /home/samba/ocr.sh
$ ll /home/samba/ocr.sh
-rwx------ 1 root root 688 Aug 27 06:39 /home/samba/ocr.sh*
動作確認
OCR処理
実際に色々なファイルを置いてみる。
- 画像から作られたPDF
- 本ページを印刷して作ったPDF(2ページ分)
- エクセルのファイル
- ワードのファイル
しばらく待っていると OCR 結果が出力された。
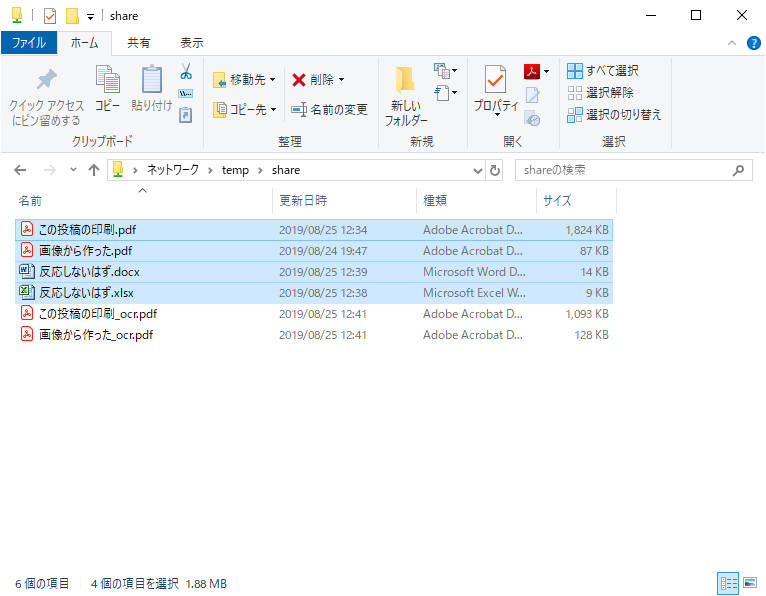
呼び出しログ。
/var/log/syslog
Aug 25 15:32:24 localhost incrond[1133]: (root) CMD (/home/samba/ocr.sh /home/samba/share/この投稿の印刷.pdf)
Aug 25 15:32:24 localhost incrond[1133]: (root) CMD (/home/samba/ocr.sh /home/samba/share/画像から作った.pdf)
Aug 25 15:32:24 localhost incrond[1133]: (root) CMD (/home/samba/ocr.sh /home/samba/share/反応しないはず.docx)
Aug 25 15:32:24 localhost incrond[1133]: (root) CMD (/home/samba/ocr.sh /home/samba/share/反応しないはず.xlsx)
できあがったファイルの属性。
$ ls -l /home/samba/share/
total 3164
-rwxr--r-- 1 nobody nogroup 13562 Aug 25 12:39 反応しないはず.docx
-rwxr--r-- 1 nobody nogroup 8917 Aug 25 12:38 反応しないはず.xlsx
-rwxr--r-- 1 nobody nogroup 1118955 Aug 25 15:32 この投稿の印刷_ocr.pdf
-rwxr--r-- 1 nobody nogroup 1867249 Aug 25 12:34 この投稿の印刷.pdf
-rwxr--r-- 1 nobody nogroup 130227 Aug 25 15:33 画像から作った_ocr.pdf
-rwxr--r-- 1 nobody nogroup 88560 Aug 24 19:47 画像から作った.pdf
なお「この投稿の印刷.pdf」は Chrome で生成したもので、元々透明文字が入っていたのだが、この処理に掛けると透明文字が一旦消されて OCR 結果に置き換わる模様。結果として、一部間違っていたり、ロゴなんかも一生懸命文字にしようとした結果が混ざり込んでいたりしてあまり良い状態ではなかった。
検索
Acrobat Reader DC で検索してみる。
編集から高度な検索を選択。
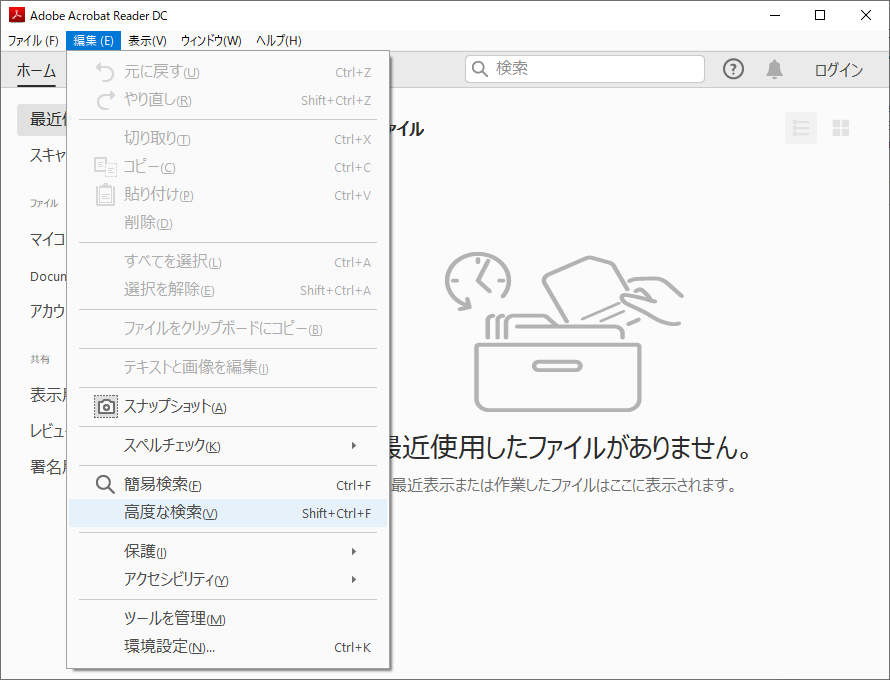
検索ウィンドウが表示されるので「以下の場所にあるすべての PDF 文書:」を選択。
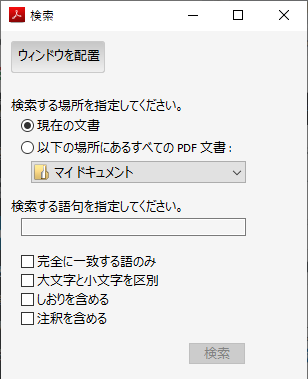
ドロップダウンリストから「参照...」を選び、フォルダー欄に
\\[ホスト名]\[共有名]
を入力してOKする。今回構築した環境では \\temp\share である。

検索する語句を入力し、検索ボタンをクリックする。

読み取り権限で見に行くよ!と宣言されるので、許可する。
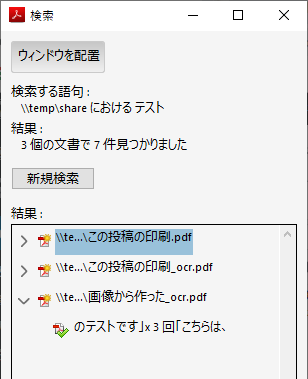
テストという文字が入っている PDF が3つ検出された。
画像から作られた PDF の文字もちゃんと検索結果として表示された。
以上で実現できた!
やったこと
変換エラー
テスト実行したところエラーが発生。
$ sudo pdfsandwich test.pdf
pdfsandwich version 0.1.6
Input file: "test.pdf"
Output file: "test_ocr.pdf"
Number of pages in inputfile: 1
More threads than pages. Using 1 threads instead.
Processing page 1.
identify -format "%w\n%h\n" "/tmp/pdfsandwich_inputfile988818.pdf[0]"
identify-im6.q16: not authorized `/tmp/pdfsandwich_inputfile988818.pdf' @ error/constitute.c/ReadImage/412.
Warning: could not determine page size; defaulting to A4.
convert-im6.q16: not authorized `/tmp/pdfsandwich_inputfile988818.pdf' @ error/constitute.c/ReadImage/412.
convert-im6.q16: no images defined `/tmp/pdfsandwich033472.pbm' @ error/convert.c/ConvertImageCommand/3258.
ERROR: Command "convert -units PixelsPerInch -type Bilevel -density 300x300 "/tmp/pdfsandwich_inputfile988818.pdf[0]" /tmp/pdfsandwich033472.pbm" failed.
Terminating pdfsandwich. All temporary files are kept.
これは、脆弱性対策とのこと。
Qiita / HomebrewのImageMagickとpolicy.xml (not authorized エラー)
単純に緩めて良いものなのかどうかがよく分からなかったけど…
stackoverflow / convert:not authorized `aaaa` @ error/constitute.c/ReadImage/453
を見てみると、convert コマンドに信頼できる情報源からのファイルしか取り込まない場合にだけ緩めたらいいんじゃないの?ということの模様。
以上のことからポリシーを緩めることとした。
読み取り精度の確認
少しでもいい感じに読み取りたいと思ったけど…パラメーターだけではあまり変えられない感じ。
テスト素材には以下の PDF を利用。最近、近隣からミサイルがガンガン打ち上げられ、国内で敵国が軍事演習をするような極めて異常な事態だし、我が国に迫る極めて重大な危機を再認識するのにちょうどいい。
総務省 / 全国瞬時警報システム(Jアラート)全国一斉情報伝達訓練の結果等

※参考画像のため、自治体名や電話番号などはぼかしてある。
パラメータ無指定
$ sudo pdfsandwich test.pdf
je]
FRSO0#4H198
4z BRP AF (J FT 7—bk) oO
£E—-FPRESIMRS Sie snET,
SEPP R UAT A J TF—b) OVERBOARD, AB BEDSAB
(CACHE SAUTPR AS, SEBRIC RATER 5 BE SNS DOMMPBGRE, 4
HO BA CFC ii LET.
“OMl@lL, FatO ARCH 4 RMS PELUCHU ET,
MRBGS CTO C, BREEZES BRVRLET,
<i ABR >
FK3O0 5AH168H (kK) FATIL1ROODw
FKS3O 8H29H0 (kK) FRI 10048
~R30411H218H (Ok) FAL 100
R314 2A208 Ok) FAIL 1 ROOD
< MRMBGEAZR >
DEVA4BFrTAD)
Saud, JF A7-hOF ARCH X 3
Pa bb6lIkE. IED SUIS EABCH
DPRFXV ARF +YTAD
XPRBReayara Jr 7—bk) bit
Hm BRCRAKER PORAIRe, BPOATMEBR PSI CRE
ILBEATAVAFACH,
(FV Adit]
DITA SW TH MBM BORER WM - KR
TEL:数字は正しく認識されていた。ハイフンが -- になっていた。
(A#R正確な数字)
日本語指定
ライブラリは tessdata_fast がインストールされたが、この場合には oem 0 と oem 2 は動作しないみたい。
Qiita / PythonとTesseract OCRで文字認識
いくつかのパターンで試したけれども1文字も変化がなかった。
$ sudo pdfsandwich test.pdf -verbose -rgb -lang jpn
$ sudo pdfsandwich test.pdf -verbose -lang jpn
$ sudo pdfsandwich test.pdf -verbose -lang jpn -tesso '--oem 1'
$ sudo pdfsandwich test.pdf -verbose -rgb -lang jpn+jpn_vert
回覧
平成0 年4 1 9 日
全国瞬時警報システム(アラト) の
全国一斉情報伝達訓練が実施されます。
全国瞬時警報システムけけアラー) の動作確認のめ、内閣官房ら全国
に配信され情報、実際に防災行政無線ら発信されるかの訓練放送を、全
国の目治体一に実施します。
この訓練、下記の日で年4 回実施を予定しおりま。
訓練放送でので、間違えないようお願い致します。
ぐ実施日> 平成30 年5 月16 日(水) 午前11 時00 分頃
平成30 年8 月29 日(水) 午前1 1 時0
分頃
平成30 年11 月21 日(水) 午前11 時0
分頃
平成31 年2 月20 日(水) 午前11 時0 分頃
ぐ訓練放送内容>
ゅ上り4 音チャイム
「これは、J アラートのテストです」x 3 回
「こちらは、自治体名です」
ゅ下り4 音ャイムゅ
※全国通時警報システム(]アラー) とは
地震・津や武力攻撃どの緊急情報を国ら人工衛星どを通じて朋時
にお伝えするシステムで
。
【問い合わせ先】
自治体の課名と係名が正しく認識できていた
TEL:数字は正しく認識されていた。ハイフンが ー になっていた。
(内線正確な数字)
メモ
出力結果に余計な空白が含まれる問題
今日も微速転進 / Tesseract OCR 近況(2018/06)
パラメーターを付けて起動すると改善する模様。
今回のサンプルでは変化がなかった。
$ sudo pdfsandwich test.pdf -verbose -rgb -lang jpn -tesso '-c preserve_interword_spaces=1'
さいごに
バージョンもパターンデータも以前やったときと一緒なんだから、結果は分かっていたものの、やはり認識精度は商用レベルとはいかない。だけど、いくつかのキーワードを検索すればヒットしそうな程度の認識はできるようになっている。結構使える!と言う人も出てくるかもしれない。っていうか、ある程度ITセンスがある人なら使えるような気がする。


コメントはこちらから お気軽にどうぞ ~ 投稿に関するご意見・感想・他